Relatório do Gartner aponta ações para simplificar e dimensionar a integração de dados com a automação assistida por metadados ativos da malha de dados
O Gartner publicou hoje (18/11) um relatório apontando que os líderes de dados e análises são cada vez mais desafiados a gerenciar seus ativos de dados crescentes em um ambiente mais distribuído. O white paper da consultoria indica uma definição de malha de dados, seus benefícios e o que as organizações precisam para adotá-la; como ela se encaixa nas abordagens existentes de gerenciamento e arquitetura de dados e fornece insights passo a passo sobre como criar um design de malha de dados combinável.
O que é malha de dados?
A malha de dados surgiu como uma solução para o desafio comum de coletar, conectar, integrar e entregar dados de fontes de dados dispersas para os usuários que precisam deles. No contexto atual de crescentes silos de dados e aplicativos, juntamente com talentos limitados de dados e análises, a infraestrutura de dados promete simplificar a infraestrutura de integração de dados da organização e criar uma solução escalável que reduz a dívida técnica (consulte também Modernizar o gerenciamento de dados para aumentar o valor e reduzir custos).
Recursos principais da malha de dados
Os benefícios da malha de dados
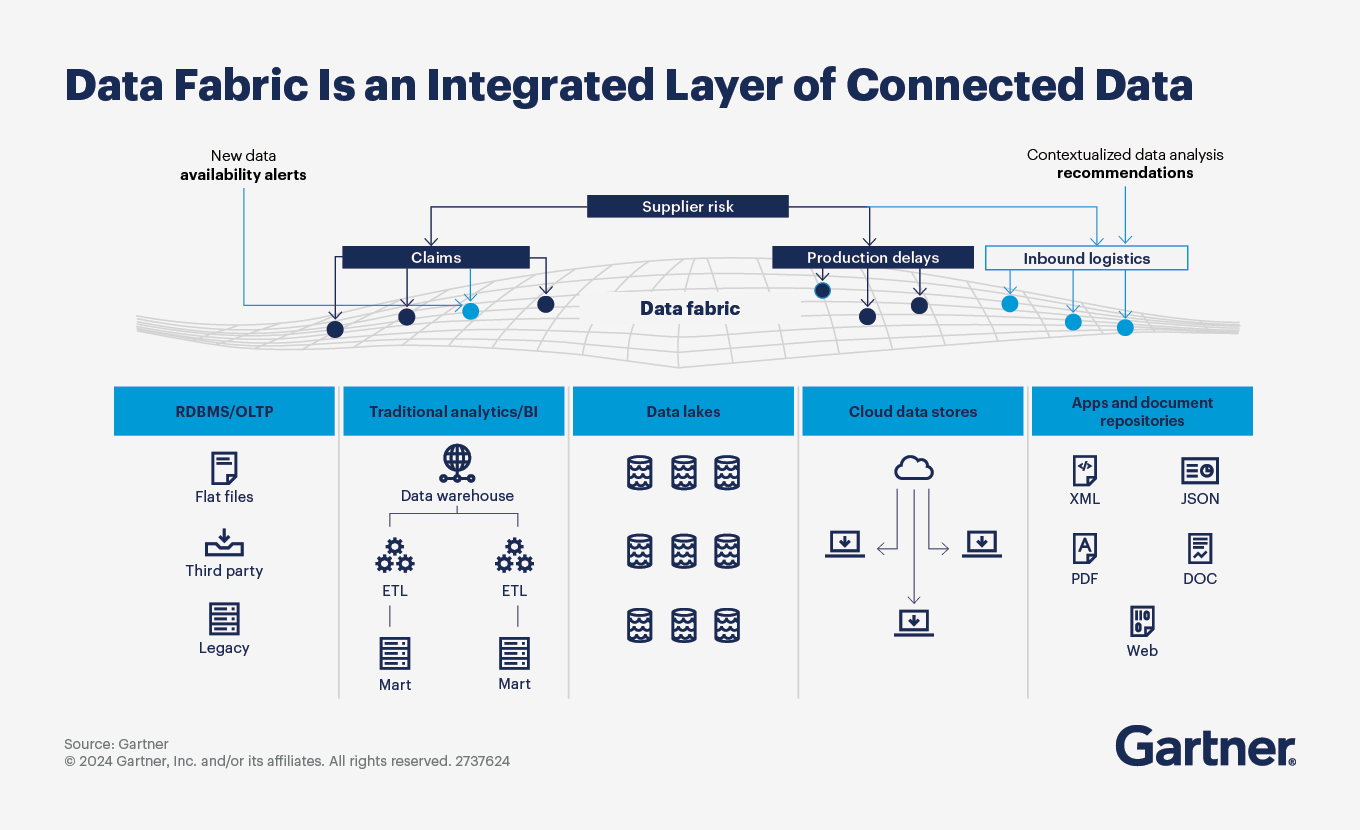
 A malha de dados atrai muitas organizações porque aproveita os metadados existentes, bem como a infraestrutura, como data warehouses lógicos. Não há “remover e substituir” com um design de malha de dados. Em vez disso, as organizações podem aproveitar as malhas de dados para aumentar (ou automatizar completamente) o design e a entrega da integração de dados, enquanto capitalizam os custos irrecuperáveis em data lakes e data warehouses existentes.
A malha de dados atrai muitas organizações porque aproveita os metadados existentes, bem como a infraestrutura, como data warehouses lógicos. Não há “remover e substituir” com um design de malha de dados. Em vez disso, as organizações podem aproveitar as malhas de dados para aumentar (ou automatizar completamente) o design e a entrega da integração de dados, enquanto capitalizam os custos irrecuperáveis em data lakes e data warehouses existentes.
Embora a infraestrutura de dados não seja uma tecnologia madura e nenhum fornecedor forneça atualmente todos os componentes da malha de dados, seus benefícios potenciais se aplicam a diferentes partes da organização, como:
- Unidades de negócios — Permite que usuários de negócios não técnicos encontrem, integrem, analisem e compartilhem dados rapidamente;
- Equipes de gerenciamento de dados — Oferece vantagens de produtividade por meio de acesso e integração automatizados de dados, bem como maior agilidade para engenheiros de dados, resultando em entrega mais rápida de solicitações de dados;
- Organização geral — Oferece tempo mais rápido para insights de investimentos em dados e análises, melhor utilização de dados organizacionais e custos reduzidos por meio de insights sobre design, entrega e utilização eficazes de dados.
Para uma implementação eficaz da malha de dados, comece com metadados
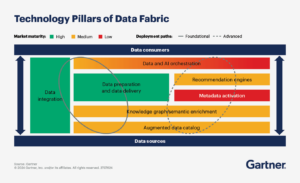 A infraestrutura de dados depende de metadados, que são os “dados no contexto” que documentam o quê, quando, onde, quem e como contextual dos dados na organização. Os metadados são produzidos como um subproduto dos dados que se movem pelos sistemas corporativos.
A infraestrutura de dados depende de metadados, que são os “dados no contexto” que documentam o quê, quando, onde, quem e como contextual dos dados na organização. Os metadados são produzidos como um subproduto dos dados que se movem pelos sistemas corporativos.
Existem quatro tipos de metadados: técnicos, operacionais, comerciais e sociais. Cada um desses tipos pode ser metadados “passivos” que as organizações coletam, mas não analisam ativamente, ou metadados “ativos” que identificam ações em dois ou mais sistemas que usam os mesmos dados. Por definição, uma malha de dados converte metadados passivos em ativos.
Como criar uma malha de dados combinável
A próxima etapa é ativar os metadados coletados executando análises gráficas neles e usando a saída para treinar um modelo de IA/ML para automatizar tarefas de integração e gerenciamento de dados. A partir dessa base, as equipes de dados e análises podem produzir gráficos de conhecimento que expõem as conexões entre os diversos ativos de dados da sua organização e seus usuários.
Por fim, as organizações podem enriquecer seus gráficos de conhecimento com semântica ou o significado e os relacionamentos comerciais nos dados. A semântica sobre os gráficos de conhecimento permite melhores análises e modelos de IA/ML mais informados.
Com essas etapas concluídas, os mecanismos de ML da malha de dados podem começar a informar e automatizar determinadas tarefas de integração de dados e atividades de gerenciamento de dados. Dependendo da sofisticação da malha de dados, o grau de automação progredirá da seguinte forma:
- Engajamento — Por exemplo, permita que integradores menos qualificados encontrem e integrem fontes de dados ou especialistas no assunto usem a pesquisa semântica para entender melhor os dados.
- Insights — Por exemplo, habilite marcação e anotação automatizadas, reconhecimento dinâmico de esquema, detecção e relatórios de anomalias, destacando atributos confidenciais para GDPR, etc.
- Automação — Por exemplo, habilite a correção automatizada de desvios de esquema, integre automaticamente as fontes de dados “Next Best“, recomende transformações ideais e promova a integração de autoatendimento aos ambientes de produção.
A malha de dados e a malha de dados são conceitos independentes que podem coexistir
Para recapitular, a malha de dados é um design emergente de gerenciamento de dados que usa metadados para automatizar tarefas de gerenciamento de dados e eliminar tarefas manuais de integração de dados. A malha de dados, por outro lado, é uma abordagem arquitetônica com o objetivo de criar produtos de dados focados em negócios em ambientes com responsabilidades de gerenciamento e governança de dados distribuídos.
Embora as malhas de dados sejam sobre gerenciamento de dados e a malha de dados seja sobre arquitetura de dados, ambas compartilham o mesmo objetivo de permitir acesso e uso mais fáceis de dados.
Algumas distinções e complementos importantes são:
- Tecnologia – Uma malha de dados pode trabalhar com diferentes estilos de integração em combinação para permitir uma implementação e um design controlados por metadados. Uma malha de dados é uma arquitetura de solução que pode orientar o design dentro de uma estrutura independente de tecnologia.
- Finalidade – Uma malha de dados descobre oportunidades de otimização de dados por meio do uso e reutilização contínuos de metadados. Uma malha de dados aproveita a experiência no assunto de negócios para desenvolver designs de produtos de dados baseados em contexto.
- Autoridade e governança de dados — Uma malha de dados reconhece e rastreia casos de uso de dados que podem ser autoritativos e trata toda a reutilização subsequente adicionando, refinando e resolvendo a autoridade de dados de forma diferente por caso de uso. Uma malha de dados enfatiza as fontes de dados de origem e os casos de uso para produzir produtos de dados combinatórios para contextos de negócios específicos.
- Pessoas – Uma malha de dados incentiva o gerenciamento de dados aumentado e a orquestração entre plataformas para minimizar os esforços humanos. Uma malha de dados, no momento, promove o design manual contínuo e a orquestração de sistemas existentes com intervenção humana durante a manutenção.
Considerando os custos da malha de dados versus malha de dados
Além disso, a malha de dados depende muito das ferramentas e plataformas de tecnologia existentes. Uma malha, por outro lado, muda o foco do custo para a entrega de serviços de dados. Na era da nuvem, os custos de dados e a flexibilidade da assinatura devem ser considerados, assim como os padrões de uso atuais e quaisquer alterações direcionais em seu orçamento e comportamento de alocação.
Para ter acesso ao white paper, acesse este link e preencha o formulário para receber uma apresentação detalhada sobre como utilizar a malha de dados para fazer um melhor gerenciamento dos dados da sua organização.